机器学习基金失败的7个原因--部分翻译兼读文笔记

这是Marcos López de Prado在9月2日的一个presentation,此公水平很高,属于学术能力和实践双优的牛人,我也是在读他的书过程中发现了这篇文章,文章下载地址:https://papers.ssrn.com/sol3/p...,国内也有不少对这篇文章的解读,有兴趣者可自行搜索,我看过的包括:https://zhuanlan.zhihu.com/p/2...和https://xueqiu.com/1518602080/...。作者将机器学习基金失败的原因总结为以下七点:
一. The Sisyphus paradigm (西西弗里神话,团队协作劳而无功问题)
-
让量化交易者独立工作的问题:
1.1 主观交易者凭主观判断及直觉而非特定的理论和逻辑工作(如果不是这样,那他们就变成系统型交易者),主观交易者的决策通常都是基于某个“故事”,且没有人能真正完全明白他们投资背后的逻辑。这并不意味着主观交易者不能成功,但他们必须独立工作,从而达到分散分的效果,如果你雇佣50个主观组合经理并让他们作为团队 作,在相互影响下,这些人的意见趋同,其结果是你用50个人的工资相当于得到一个雇员的效果;
1.2. 将这种独立工作的思路用于量化或机器学习项目时,同样有问题,如果雇佣50个博士,让他们独立工作并在6个月内提交工作成果,其结果通常是每个人都疯狂的寻找交易机会,其产出通常是:(1)拥有亮丽回测结果的过度拟合;(2) 标准的因子投资,策略已经被太多投资人使用不能产生高sharpo,但至少有学术支持。这两个结果都会让投委会在失望中取消项目。即使这50人中有5人发现了真正的机会,5个人的收益也无法覆盖50人的支出,从而这5个人也要另谋高就。让量化研究员独立工作或开发单独的交易策略,无异于缘木求鱼。
 image.png
image.png
旁注:按我的理解,除了克服人性的弱点,在技术上,量化的一大功用就是可以将不同的投资和交易维度应用于多个不同的市场和时间周期,从而达到更优的结果。量化交易应该是从基本面、技术机、消息面等不同维度寻找拥有概率优势或波动性平抑的机会,因此,在我看来,对于量化交易而言,团队协作尤为重要。
- The Meta-Strategy Paradigm,推荐的解决方案,我的理解就是一种量化分工管理方式,单独介绍这上范式的文档地址:https://papers.ssrn.com/sol3/p...:
2.1 开发实用交易策略的过程非常复杂,包括:
–Data collection, curation, processing, structuring(数据收集、修正、预处理、结构化)
–HPC infrastructure(高性能计算基础设施)
–software development(软件开发)
–feature analysis(特征分析)
–execution simulators(模拟执行)
–backtesting, etc.(回测,等步骤),
即使公司在所有这些环节提供资源共享,策略研究人员仍像一个人负责在宝马厂利用工厂提供的工程,一个人负责造一辆车(这一周是焊接工,下一周是电气工程师,再一周是机械工程师,再下一周是油漆工,如此循环周而复始而成效甚微)。
2.2 开发一个实用的交易策略所消耗的精力与开发100个差不多,每一个我所知的成功量化团队都采用Meta-Strategy Paradigm。量化团队应该遵从以下流程:
–将量化开发的过程分解为多个子任务
–量化工作的质量按子任务分别监督和评价
–每个宽客专注于自己的子任务,争取在子领域做到最好,同时对全流程有整体的认识
2.3 Meta-Strategy Paradigm概述:
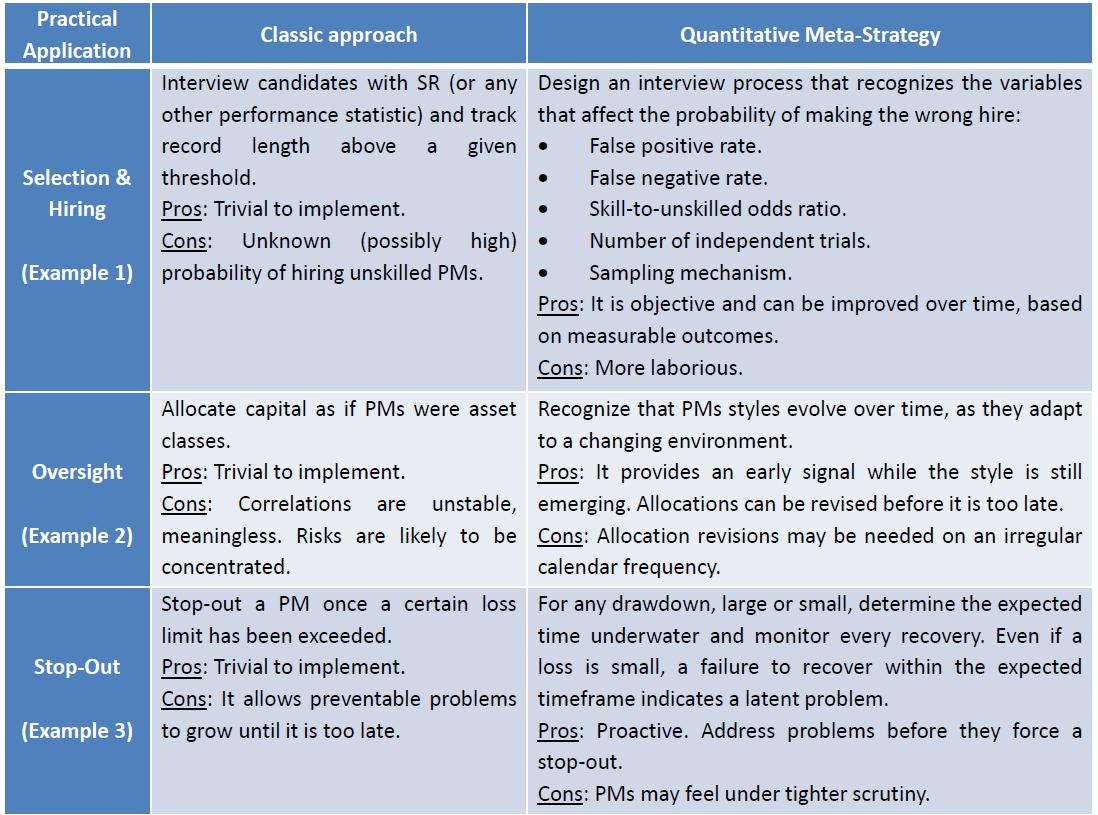 image.png
image.png
二. Integer Differentiation (整数差分): - 稳定性和记忆性的两难:
1) 在用交易数据进行推理分析时,通常的做法包括:
–returns on prices (or changes in log-prices) 价格回报(或对数回报)即一阶差分
–changes in yield :收益率变化(即二阶差分)
–changes in volatility:波动率变化(即三阶差分)
2)上述操作使时间序列稳定,代价是去除数据中包含的记忆
3)记忆是模型预测能力的核心,比如均衡模型需要记忆功能评估价格在多大程度上偏离长期预期值,从而做出预测;
总结一下,两难问题的根源在于,回报更加稳定但不具备记忆,价格有记忆但不稳定。 -
作者提出的解决方案:Fractional difference(分数差分/分形导数),这个概念我不太懂,有时间要补一下,下图是作者给出的示例图.
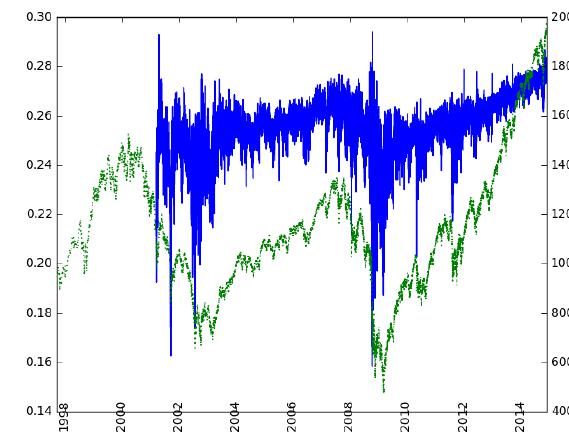 image.png
image.png
•绿线是:E-mini S&P 500 期货柱状图
•Blue line: 分数差分的结果(d=0.4)
分数差分的结果是,其在短期与收益率更加相近,在长期保持更多价格特征,从而解决这一两难问题。
三.低效取样:
1.按时间顺序取样存在的问题:
通常分析中,都是根据固定的时间周期对市场数据进行加工和取样,如日K线,30分钟K线,但市场并不以固定熵流动,也即这样取样得到的数据中,每一个样本点中包含的信息量不同(注:在交易的实际场景中确实如此,比如交易员通常更关注开、收盘30分钟或有异动(如价格形态的向上突破,5分钟钏波动率急剧增加,出现大阳线或大阴线)的指数和股票),在报表公开时,研究员也通常更关注有业绩惊喜的股票,而不是根据时间在不同的交易品种间平均用力)。
2.解决方法:不再按时间对市场数据进行划分(如每天一根bar),转而用交易量、成效额、波动率、信息熵为bar划分的基本单位。
旁注:技术分析中,也有一些针对时序取bar问题的处理方法,包括:拉时威廉斯对inside day、outside day的处理;缠论中将走势的最小单位处理成顶底分形和笔;一目均衡表中,只记录创新高新低的bar,作者的这种处理办法,按成交额或成交量分bar,使bar中同时包含价量信息,通过波动论、信息熵划分bar,这些思路都值得实践,如果要把工作做到这个粒度,也确实需要作者在前文中说到的 Meta-Strategy Paradigm。
四. Wrong Labeling(标注不当). -
存在问题:量化工作者对于特征或预测结果通常以下述方式进行:
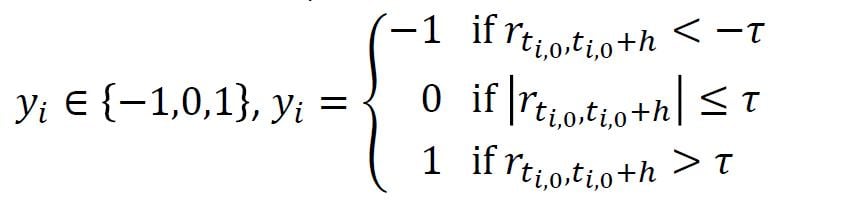 image.png
image.png
旁注:这种作法非常常见,如将利润增长率>20%标注为快速增长;在用回归方法对股票未来一周涨跌进行预测时,将>3%,标为1(上张),将<-3%标注为-1(下跌),将其余标注为0(不确定);
这一做法的一个缺陷,仍是作者在“三‘中提到的time bar的缺陷,另一缺陷在于这种做法未考虑波动率的不同(注:也未考虑市场环境,股价在先走势等上下文环境的不同)。 -
解决方法:The Triple Barrier Method(三重界线法,我的理解就是一种利用时间和价格的过滤器):
2.1 方法的思路来源:构建一个在大多数基金、交易所(通过margin call,追加保证金通知)、投资者止损离场的位置建仓的头寸几乎是不可能的
旁注:这种说法也许不适用于在市场低估、投资人恐惧到高点处加仓的价值投资者,擅长反向思维的作空者,在我的理解,在市场上盈利,要在大多数时间顺着羊群的方向顺势而为,在拐点处止损,但如果一个交易策略追求相对多的交易机会且希望大多数时间持有仓位,那么上述说法我也同意;
2.2 方法的内容:简单的说,该方法就是说固定一个窗口,例如窗口大小为N,在这段价格区间中,价格先达到上沿就标记1,先达到下沿就标记-1,到窗口结束都被碰到就标记0,也即三分类,其中,上下沿分别代表止盈、止损价,具体价位由动态预期波动率定义
(旁注:作者未给出预期波动率的具体算法,用波动率过滤市场噪音是非常常用的方法,也是很多交易策略成败的核心问题,此处大有可研究之处,标准差、ATR、Implied volatility等都可以试试;细思作者这个思路,由于大部分机构和专业投资者对止盈损的定义中,通过开仓价或某一重要技术位置如前低、前高、20日均线加上N倍波动率是一个经典设置,作者大有通过这个来反推市场上大部分参与者的止盈止损位的意思,这一方法是否适有于散户为核心的国内市场也需要注意,因大部分散户很少思考止盈、止损的问题,即使考虑止盈损也很少综合考虑市场波动率)
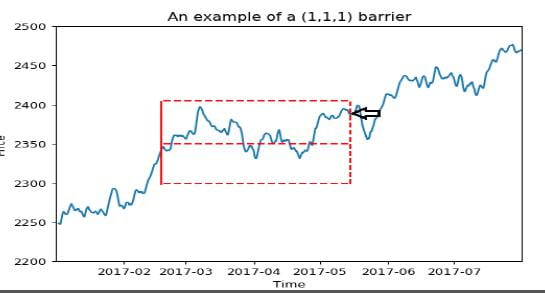 image.png
image.png
2.3 三重界线标注法(作者以下称之为Meta-labeling)有利用提高模型的F1 Score(即准确性):
先构造一个高召回(即使准确率不高)的模型,再通过Meat-labeling提高前述模型的准确率(我的理解就是用meta-labeling做交易信号的Filter);
2.4 Meta-labeling(以下称为元标签)成为有力工具的原因:
–. 机器学习模型常因为“黑盒”性质而受到诟病,元标注允许我们将机器学习系统构建在白箱之上(元标注的处理方式,有着明确的业务解释,即基于波动率定认价格区间并区分市场噪音,一些基金公司用机器学习选股,用经典的技术交易或其它量化系统择时,也是一种将黑盒子建立在白盒之上的方法)
–过度拟合的情况得到抑制,因为机器学习只决定你的仓位而不是你的交易方向(多空)(这一句未完全看懂,我的理解是交易信号由元标签产生,因此交易方向不受机器学习影响,仓位由机器学习决定是怎么回事儿?其指的是仓位与机器学习模型的召回有关吗?)
– 在轻仓时高胜率、重仓时低胜率会最终毁了你,合理的分配仓位与发现交易机会同样重要,因此,开发专门的机器学习模型专注于仓位分配是值得的
(在我的理解,资金管理比交易信号还要重要,实际上,对于风控和资金管理的关注度经常被我用来区分新手和老手)
五. Weighting of non-IID samples 对于非独立同分步样本加权
这部分未完全看懂,更谈不上理解与印证,留个空间,未来有了新的理解再来补这一部分。
六.Cross-Validation (CV) Leakage(交叉验证泄漏)
- 为什么交叉验证在金融应用中经常失效:
• 一个原因在于金融数据不服从独立同分布的假设
•当训练集中包含的信息中也出现在验证集中时,泄漏发生;
对于信息泄露,作者举了如下例子:
•假设X序列相关,而Y源自部分重叠数据,由于序列相关性𝑋𝑡≈𝑋𝑡+1.,由于数据部分重叠𝑌𝑡≈𝑌𝑡+1,当我们分别将t和t+1放入训练和验证集时,发生信息泄露。当用𝑋𝑡+1预测𝑌𝑡+1时,我们很可能得到𝑌𝑡+1=E𝑌𝑡+1 ,即使X与Y实质上并不相关。当存在 不相关特征时,信息泄漏使我们得出错误的发现。(感觉上是伪相关的一个特例?) - 简单的说,作者的意思就是说划分训练样本和测试样本的时候,训练样本结束的那些样本,因为预测未来的收益率,肯定会跨越到测试样本中,这样会有重叠,这部分样本一部分在训练中一部分在测试中,会不行。
注:这个问题,我体会不深刻,也没处理过,有机会实践后再做评论。另,近来看到一个工作思路,由于金融交易数据本身的相对稀缺性,不管如何做数据切割和交叉验证都会存在问题,他们的做法是通过分布以及tick级别数据特征,模拟交易数据(我的理解也即一个解决一个生成问题)所以交易策略在模拟数据上研发和调参,对于在模拟数据中表现良好的策略在真实数据全集上进行策略实验,并将在真实数据上表现不好的策略舍弃。
七. Backtest Overfitting(回测过拟合): - 问题描述:由于数据挖掘等种种因素的存在(容易过拟合也是机器学习在数据挖掘中广为提及的一个问题);
2.总的说来,作者提出一个公式DSR(具体工作基于这个链接:https://papers.ssrn.com/sol3/p...),以弥补传统Sharpe Ratio的不足:
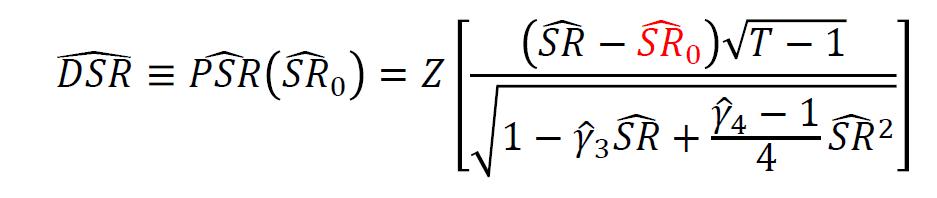
其中:
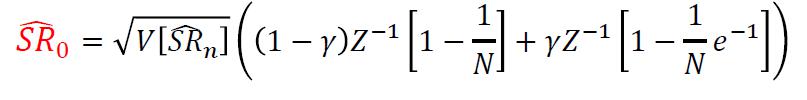 image.png
image.png
传统的夏普比例仅考虑收益的均值和标准差,
DSR 通过考虑更多信息改进SR,包括:
–收益的非正态部分 (𝛾 3,𝛾 4)
– 收益序列的长度( 𝑇)
–数据挖掘量( V𝑆𝑅 𝑛)
–选择交易策略的独立实验数量 𝑁
旁注:知乎上的作者认为如果只是筛选模型,比如对比两个模型的夏普比,选高的那个,只是排序作用,不需要太精确的值,所以也不必太在意。我认为正因为多数基金的业绩比较甚至开发的目标函数都以夏普比率或类夏普比例的指标为基础,多一个信息更全面的评价维度总是好的,DSR作为一个策略筛选标准是否有效,等我在实证中用过再做评价。
Reprinted from 简书,the copyright all reserved by the original author.
Disclaimer: The content above represents only the views of the author or guest. It does not represent any views or positions of FOLLOWME and does not mean that FOLLOWME agrees with its statement or description, nor does it constitute any investment advice. For all actions taken by visitors based on information provided by the FOLLOWME community, the community does not assume any form of liability unless otherwise expressly promised in writing.
FOLLOWME Trading Community Website: https://www.followme.com


Hot
-THE END-